
Machine Learning
December 08, 2023

In the field of Natural Language Processing (NLP), large language models have changed how machines work with human language. Models, like GPT-3 and later ones, have shown great skills. They can translate language, summarise text, answer questions, and even write creatively. But there's a hidden part that's vital for these models to work well – tokenization.
We often forget about tokenization. But it's the step where text is broken into smaller pieces called tokens. This article throws light on tokenization in large language models. It shows why it's important and how it helps models manage the bulk of written data.
Tokenization, in simple terms, is turning a string of text into parts or 'tokens.' Tokens might be whole words, fragments of words, or even single letters! What you pick depends on how detailed you want your tokenization to be. Its purpose? To help computers process text better by splitting it into its basic bits!
Turning uncut text into smaller bits is called tokenization, a key part of natural language processing (NLP) applications. These small bits are called tokens. Tokens might be words, pieces of words, or even single letters, depending on the language or NLP task at hand.
Why is this important? It helps make the raw text easier to handle for NLP systems. Once the text is broken down into tokens, NLP applications can understand the language better. This understanding helps pull out key details and insights from the text, and this is vital for many NLP uses.
Tokens are key parts of how NLP models work. They are the foundation for understanding language and the way they are ordered and their context aids machines in understanding the text. Tokens offer a structured view of text that aids in tasks like emotion detection, translation, and creating text.
A key part of tokenization is how it helps spot feelings. Emotions in words mostly come from the words we choose, how we put our sentences together, and the situation. Tokens are great at grabbing all these pieces, that way NLP algorithms can tell what emotional hints are there in the text. They can tell about the vibe behind a product review or the mood in a post on social media. This skill is very useful for things like sentiment analysis, keeping an eye on social media, and looking at what customers say. Knowing the emotions in the text is super important.
In simple terms, tokenization is like a tool for machine translation. It helps change words and phrases from one language to another while keeping the same meaning. Due to tokens, language models can break down language barriers, making talking easier worldwide. Also, tokenization is handy in creating sentences that make sense and fit the context. Tokens can help, whether in making chatbot responses sound more human or helping a word processor finish your sentences. This makes the text made by the NLP model even better!
Big Text Models (BTMs), like GPT-3, handle lots of text data. They split the huge amount of text into parts, which is nothing, but considered as tokens. Then, these tokens are used as input. These models train on a wide array of texts. Cutting up the text into tokens helps them deal with enormous datasets effectively.
Tokenization is just like finding a hidden key. This key lets us train large language models. Big or "Large-scale" language models are the brain! It transforms text into tokens. Tokens help manage tons of data, splitting it into small pieces. Now, the model's brain power can handle it. So, no information is too big to deal with. Tokenization allows us to train with huge amounts of text.
Think of tokenization as a smart breaker, splitting huge data sets into tiny, easier to handle pieces, called tokens. It chops up text, which lets even the biggest and most tricky text collections be used by language models. This big deal in NLP is it gives the capability to work with giant datasets, and this boosts its language understanding and knowledge-sharing abilities.
Tokenization is essential when dealing with big datasets. It empowers language models to deal with a lot of text and learn human language nuances. It makes handling large data easier and aids the training process. More data means language models can understand more, be more sophisticated, and be aware of the context. This helps language software with tasks like chatbots, translation, and content creation. In short, tokenization helps language models reach their full potential with the increasing amount of available text data.
Splitting text into tokens brings many benefits for large language models. It allows for handy data display and handling, meaning that models can better understand language trends and make sense of text. Plus, it helps in dealing with memory and computing power, making models stronger and easier to grow.
Tokenization helps make language models work well with different apps. It's like having a standard language that makes it easy to share data between various text analysis tools. From healthcare to banking, language models can easily fit in as they understand the orderly tokenized input. This helps smooth conversation between different systems and text analysis models.
Tokenization is an important step, but it has its drawbacks. A big issue is that tokenization can result in missing information. This often happens with languages or texts that depend heavily on context, subtle meanings, or unusual formats. Tokenization also has trouble managing words not in its vocabulary or language based on characters.
Language has repeating structures and links. Structures and links can be about grammar, meaning, and the connections between words or phrases. In Natural language processing (NLP), seeing and getting these patterns is needed for doing tasks. Some tasks are, tagging words, recognizing named entities, and analysing sentiment.
Tokenization helps in understanding how language works. It splits text into bits called tokens. This way, NLP models can look at word sequences and how they connect. This step makes it easier to pull out key parts and patterns from the text. It's super important for things like figuring out feelings from text and creating a new language.
Language patterns play a key role in NLP. They help in tasks like finding information, classifying text, translating languages, and creating chatbots. In translation, recognizing the language patterns of both initial and final languages helps create correct translations. However, in the context of NLP and ML, Language patterns have some popular applications across different domains such as:
Other than those mentioned above, apps like Search Engines, Speech Recognition, Named Entity Recognition (NER), Text Classification, Code Generation, and more are some popular apps that make NLP a must-have component of intelligent systems and applications development.
Tokenization is a crucial preprocessing step in NLP that uses different splitting approaches, from basic space-based breaking to complex tactics like fragment breaking and binary-code pairing. The kind of breaking method to use totally relies on the NLP task, language, and data set you're working with. Here are some common Tokenization Methods Used in NLP mentioned below:
1. Word Tokenization breaks sentences into words and it is one of the most common form of tokenization:

2. Sentence Tokenization breaks text into sentences.
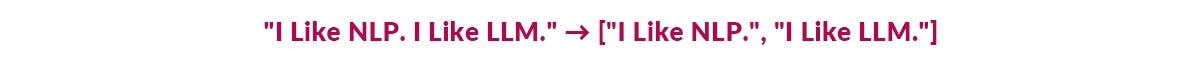
3.Subword Tokenization divides words into smaller units. This is particular for morphological variations.
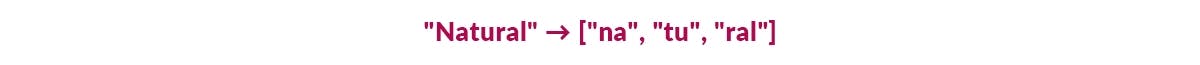
4.Character Tokenization breaks text into individual characters.

4. Byte Pair Encoding (BPE) is an iterative algorithm that usually combines the most frequent pair of consecutive tokens to create a vocabulary.

Other than the above mentioned, there are NLTK and SpaCy Tokenizers, WordPiece Tokenization, Regular Expression Tokenization, Treebank Tokenization, and more.
Various ways of breaking down text have pros and cons. Splitting words based on spaces is simple, but might not work well for languages that stick words together or change words. Methods like Byte-Pair Encoding (BPE) and WordPiece are better for languages with intricate grammar. Checkout below image for more understanding:
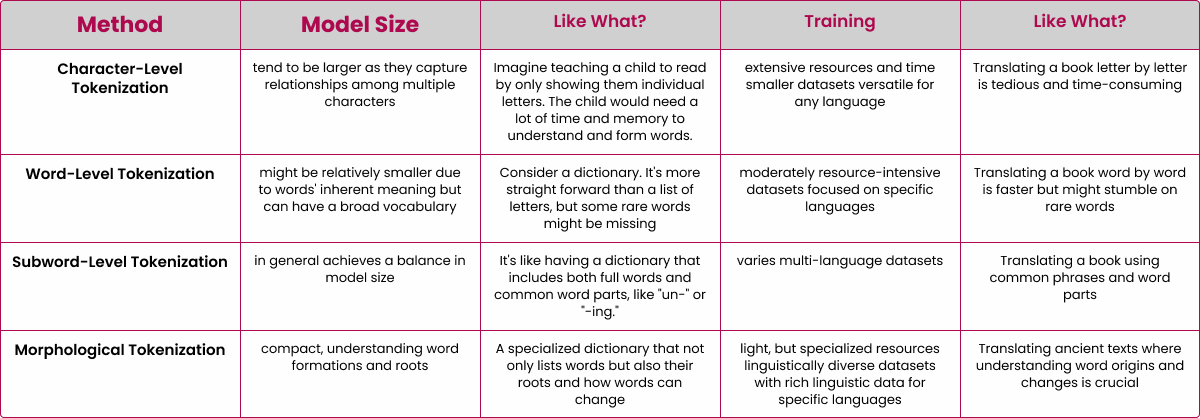
Tokenization acts as the base for text preprocessing. It changes everyday text into data that is easy to manage. It preps the text for NLP activities such as understanding emotions, classifying text, and finding information. In addition, Tokenization in text preprocessing is a must for several reasons:
Stacking tokenization with text cleaning and making text normal improves text quality. It's about taking out unnecessary noise, special characters, and pointless information. It also involves making text standard by using different methods. Being a vital step in NLP tasks, Cleaning and normalising text helps to minimise the count of unique tokens present in the text. In addition, it also removes the variations in a text and also cleans the text by eradicating redundant information. Stemming and lemmatization are two well-known methods used for normalisation.
In NLP, feature engineering plays a vital role and depends a lot on tokenization. NLP workers break down the text into tokens. They then pull out useful features that help machine learning models work better. Tokenization in feature engineering mainly includes changing the existing features or creating new features to enhance the ML model’s performance. Below are some examples of the contribution of tokenization in feature engineering:
Breaking up text and large language models are used in lots of areas. They help with tasks in health, money matters, online shopping, and making content. These tools change business by making text work automated and allowing new ways for humans and machines to interact. Let’s understand through the following are some of the real-world applications of tokenization and language models.
NLP work gets a big help from tokenization. This method is used in different uses, such as:
In terms of achieving success with tokenization, a noteworthy example is its use in medical research. Through the implementation of tokenization techniques and large language models, medical literature analysis has undergone a much-needed boost, paving the way for quicker drug development and the possibility of new therapies for different illnesses.
Even though Large Language Models (LLMs) have achieved major benchmarks, we must be aware of their certain limits, lines, and possible risks. Understanding these boundaries helps us to make smart choices when using LLMs responsibly.
Breaking down language with many word forms can be tough. Also, keeping up with different methods of text division is challenging. Plus, it's important to ensure that text division techniques can change with the language's changing versions.
One key setback involves handling OOV words. Tokenization uses a preset word list, and OOV words can lead to flawed or incorrect portrayals. Methods like breaking words into smaller parts and growing the word list as needed help overcome this problem.
Tokenization can impact how we understand a model, making it hard to link the created text to its initial form. This becomes particularly important in areas like law document study or medical reports, where clarity and responsibility are vital.
So, tokenization is very important in Natural Learning Processing - it's key for large language models to work well. It allows them to handle loads of text quickly, learn how language works, and do well in different NLP jobs. Tokenization is like the unnoticed strong base in NLP's sphere. Its impact on language models is very important. As NLP technologies keep growing, tokenization ways will also grow, leading to deeper language understanding. All because of continued study and creativity, we're at Codiste set to see amazing uses and breakthroughs in Natural Language Processing.
Codiste, a top NLP solutions company, totally gets how essential tokenization is for improving large language models. Our engineers have gained a deep understanding of large language models that enable them to handle loads of text quickly, learn how language works, and do well in different NLP jobs. Want to drive towards innovation with applications with LLMs? Let’s connect to talk about how we can implement LLMs into your project. Contact us now!



Every great partnership begins with a conversation. Whether you're exploring possibilities or ready to scale, our team of specialists will help you navigate the journey.