Generative adversarial networks have fundamentally altered deep learning, especially for crafting highly realistic synthetic images. StyleGANs represent a category of adversarial networks that integrate an innovative style-oriented generator structure to attain unseen oversight over visual qualities in generated images.
In this piece, we will investigate precisely what StyleGANs are, their design and pivotal parts, different variations of StyleGANs, how they develop past conventional adversarial networks, their capabilities, strengths, and limitations.
What are Style Generative Adversarial Networks (StyleGANs)?
StyleGANs are GANs that use a style-based generator to produce high-quality images with fine-grained control over their visual attributes. Developed by researchers at Nvidia, StyleGANs introduce an intermediate latent space (W space) between the input noise vector (Z space) and the generator. This W space consists of style vectors that are fed to each layer of the generator, allowing granular control over styles at different resolutions.
The key benefit of this architecture is disentangled representations in the W space leading to realistic image synthesis and editing applications. For instance, modifying a single style vector can change just the hairstyle in a face image while keeping other facial attributes constant. This level of disentanglement and control sets StyleGANs apart from traditional GAN architectures.
Traditional GANs consist of two neural networks - a generator (G) that creates synthetic images from random noise and a discriminator (D) that tries to distinguish between real and synthetic images. They are trained adversarially where G tries to better fool D over time.
Foundation of StyleGANs
- An intermediate mapping network between input noise (Z) and the generator (G). This produces the style vector (W) by mapping Z via multilayer perception (MLP).
- W vectors are then transformed into styles via learned affine transformations and fed to layers of the synthesis network (the generator G).
- Stochastic variation is introduced within G via per-pixel noise injection after each convolution layer.
- A technique called style mixing regularises the generator by combining styles from different inputs.
This architecture allows granular control over visual attributes at various scales leading to high-quality image generation and editing capabilities.
Types of StyleGANs
1. StyleGAN
- The original StyleGAN architecture introduced key innovations like the intermediate mapping network, style-based generator, and AdaIN.
- Produced high-quality images but suffered from training instability and artefacts.
- Used progressive growing and style mixing regularisation strategies for improved results.
2. StyleGAN2
- Architectural changes like removing progressive growing and using skip connections improved image quality and training stability.
- Reduced common artefacts through new regularisation techniques.
- The training was more reliable across a wider range of datasets compared to StyleGAN.
3. StyleGAN2-ADA
- Introduced adaptive discriminator augmentation (ADA) to regularise discriminators better.
- ADA makes the discriminator trainable with limited data and improves quality.
- Enhancements like discriminator data augmentation and lazy regularisation further boost results.
4. StyleGAN3
- Refines the StyleGAN2 framework further for best results.
- New generator regularisation and noise injection techniques reduce artefacts.
- Drastically improved training speed through executor neural network parallelism.
- Latent space is more disentangled leading to better editing control.
Among these iterations, StyleGAN2 and StyleGAN2-ADA offer the best trade-off currently between image quality, training stability, and ease of use for most applications. StyleGAN3 pushes advanced image generation quality but requires more skill to train properly.
Comparison of StyleGAN models
As we can see, StyleGAN2 made pivotal progress in image fidelity and training reliability over the initial version. Subsequent releases have continued to push the best in image generation quality.
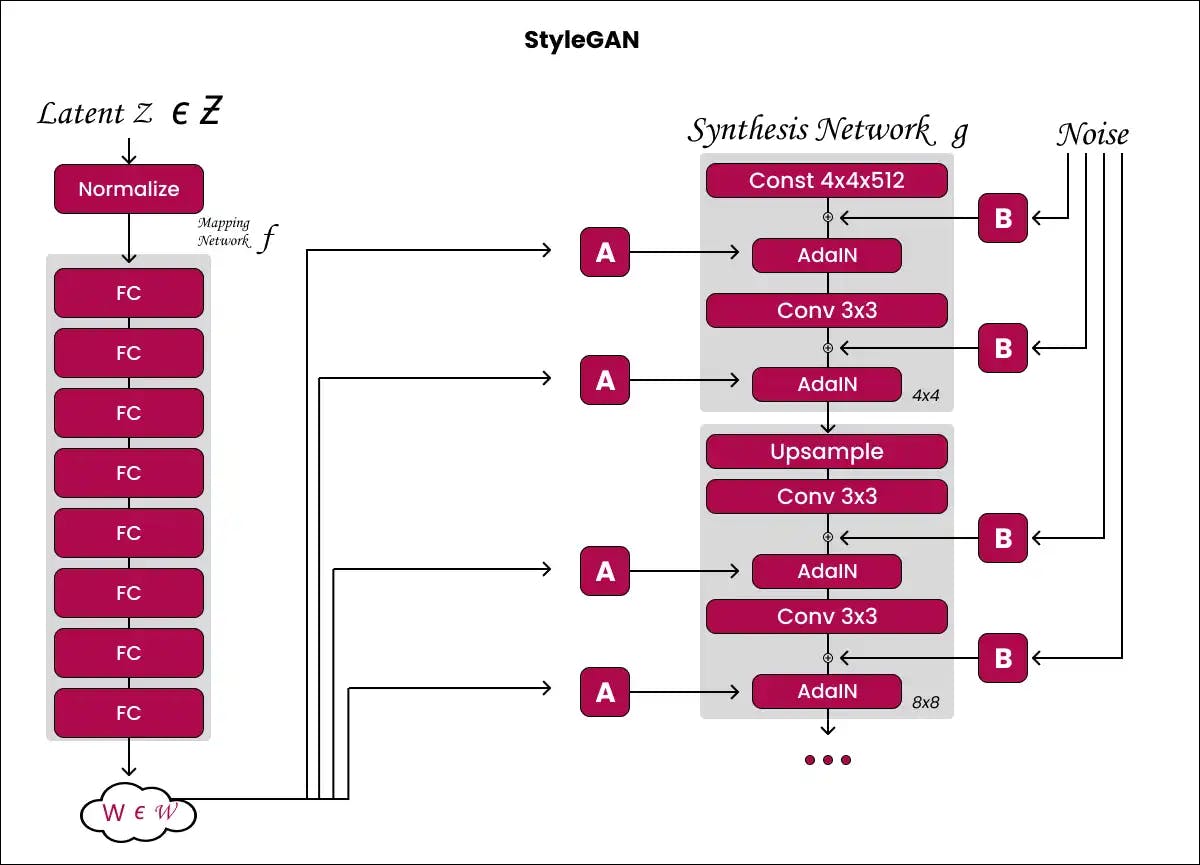
Key Components of StyleGAN Architecture
Now that we have understood the high-level picture, let's take a look at some of the key components of a StyleGAN network:
The Generator Architecture
The generator is the most crucial component of any GAN. In StyleGAN, the generator consists of two main subnetworks:
- Mapping Network
Changes the input noise vector (Z) to an intermediate latent space (W) via an 8-layer MLP. - Synthesis Network
The actual generator consists of convolutions. It takes in W vectors transformed into style vectors via affine transformations to generate the image through upsampling. Noise is injected at each layer to introduce stochasticity.
By separating mapping from synthesis, StyleGAN allows fine-grained control over image attributes through styles (W space) while generating variability through noise injection.
The Discriminator
The discriminator performs adversarial training against the style-based generator. It tries to classify synthetic vs real images. StyleGAN uses a convolutional discriminator architecture similar to Progressive GANs. Enhancements in recent versions like StyleGAN2-ADA also augment the discriminator via mixing styles, noise injection, etc. to improve training stability.
Latent Space (W Space)
The intermediate W space produced by the mapping network is a key innovation in StyleGAN. It leads to disentangled style representations that offer granular control over visual attributes (hairstyle, pose, eyes, etc.) in generated images. This enables powerful image editing and synthesis capabilities using semantic latent directions. The extent of disentanglement in W space differentiates the quality of StyleGAN versions, with recent releases like SG3 producing highly disentangled representations.
Concept of Style-Based Synthesis
Style-based synthesis is a breakthrough technique introduced by StyleGAN where styles defined as vectors in an intermediate latent space (W space) are fed to layers of the generator. This grants fine-grained control over visual attributes at different resolutions in the generated images.
This works by first using a mapping network to convert the input noise vector (Z) to the latent W space. Dimensions in this W space learn to represent specific visual styles like hair, eyes, pose, etc. in a disentangled manner.
These style vectors are then transformed via learned affine transformations into style information that modulates the normalised feature maps in the synthesis network (the actual generator).
The adaptive instance normalisation (AdaIN) approach enables this style-based control over feature activations. AdaIN allows each style vector to control visual features corresponding to a particular resolution in the synthesis network by modulating the activations.
For example, the early layers that generate coarse 4x4 feature maps are controlled by styles governing high-level attributes like pose, general hairstyle, etc. The deeper layers working at higher resolutions are then controlled by styles that can manipulate finer facial features.
This differs fundamentally from traditional GANs where noise vectors(Z) are directly fed to the generator network. Without intermediate mapping/style transformation stages, traditional GAN generators lack such fine-grained resolution-specific control over attributes.
Modifying a noise vector in original GANs causes ambient changes in generated images. But StyleGAN's style-based approach supports targeted semantic manipulation, e.g. changing only hair color while keeping all other facial attributes unchanged. This enables practical applications in image editing.
So in summary, binding intermediate style vectors to generator layers is the key idea that gives StyleGANs their powerful control over visual attributes in generated images.
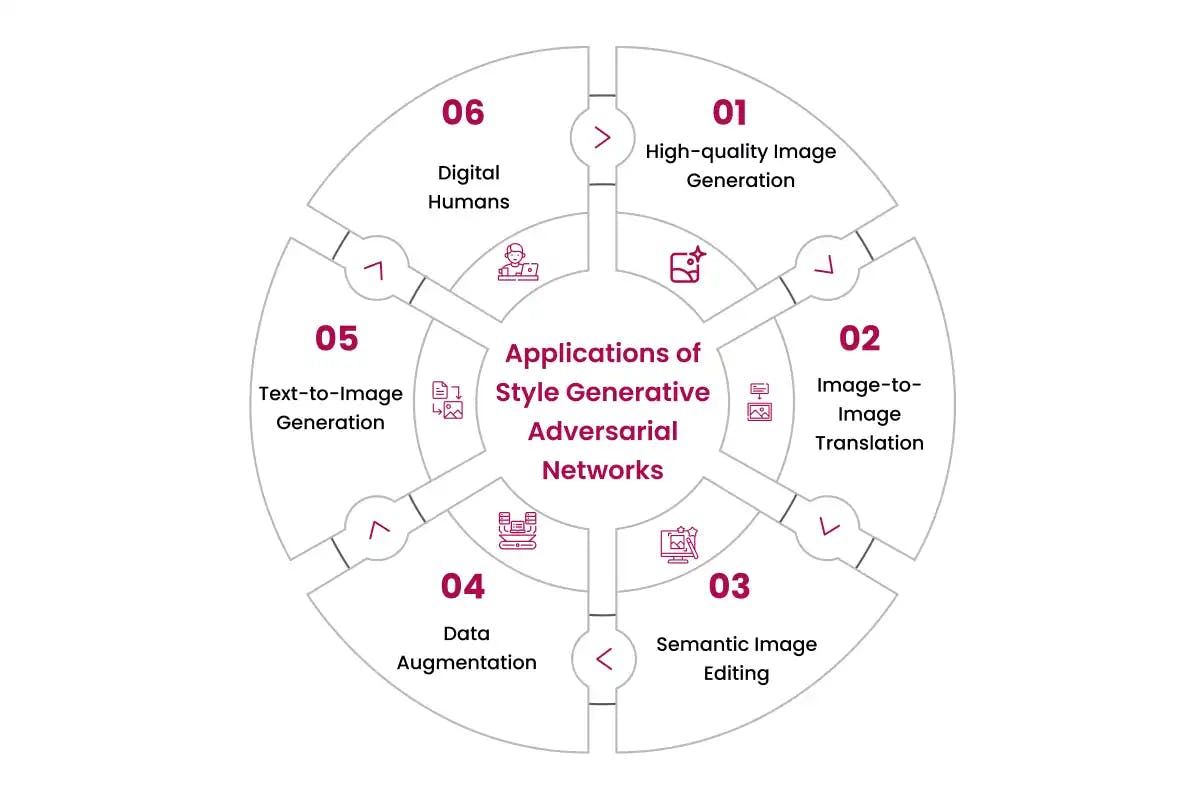
Applications of Style-Generative Adversarial Networks
1. High-quality Image Generation
- StyleGANs can generate stunningly photorealistic and diverse images across domains like faces, landscapes, paintings, etc.
- The volume and variety of images that can be produced is virtually extensive while preserving photographic fidelity.
- Enables applications like generating immense personalised avatars, fantasy art, and simulated environments (bedrooms, cities, etc.).
2. Image-to-Image Translation
- Powerful image-to-image translation models can be built by fine-tuning the StyleGAN framework with dual datasets.
- Some examples include translating sketches to finished paintings, B&W to colour images, low-res to hi-res, unmasked to masked faces, etc.
3. Semantic Image Editing
- Manipulate visual attributes seamlessly by moving across disentangled latent directions, e.g. change hair colour, age face, modify the expression, rotate face.
- Unlike traditional GANs, StyleGANs allow granular localised edits while retaining unrelated facets, enabled by the disentangled style space.
4. Data Augmentation
- Real-world datasets often suffer from a lack of volume and diversity hampering ML model performance.
- StyleGANs allow synthesising unlimited varied, high-quality synthetic images to overcome data scarcity issues and improve downstream model training.
5. Text-to-Image Generation
- By fine-tuning unconditioned StyleGANs on text-image pairs, new models can generate images from text prompts like "an oil painting of a clock tower".
- A bridge between language and visuals opens doors for illustrations from stories, text to art generation, etc.
6. Digital Humans
- Highly personalised and photorealistic avatars can be created by fine-tuning StyleGANs on a few images of a person and interpolating intermediate latent vectors.
- Digital lookalikes find applications in VR/metaverse platforms, video game characters, animated content creation, etc.
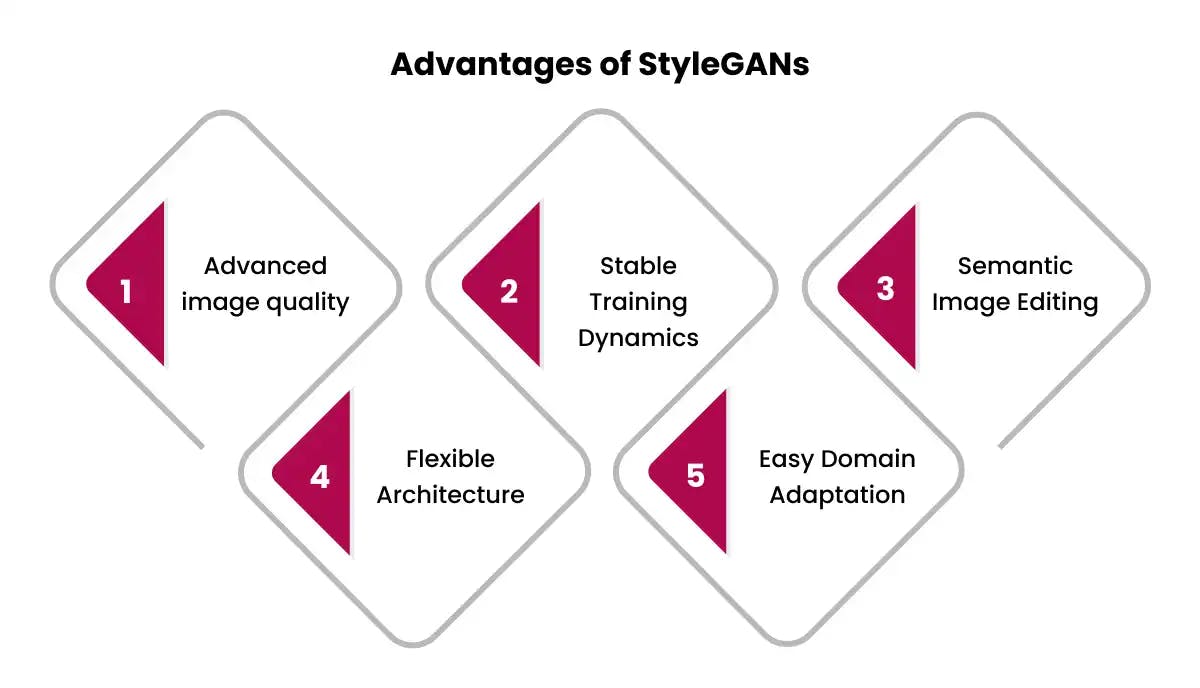
Advantages of StyleGANs
1. Unprecedented Image Quality and Attribute Control
- StyleGANs achieve advanced image quality surpassing other GAN variants. Facial and full-body images generated are often indistinguishable from real photos.
- Granular control over visual attributes like hairstyle, pose, expression, etc. is enabled through style-based generator architecture and disentangled style vectors.
- Every minute attribute can be tuned by manipulating specific style vectors in the W latent space without affecting other attributes. This level of control is unmatched by other GAN models.
- Enables semantic image editing applications like changing only facial hair while retaining identity, age, other facial features, etc.
2. Reliable and Stable Training Dynamics
- Improving training stability was a key focus in later StyleGAN editions. StyleGAN2 and beyond models can reliably achieve convergence across datasets.
- Regularization techniques introduced at architectural and objective function levels stabilize training dynamics. ADA in StyleGAN2-ADA further optimizes convergence.
- Reduced failure rates limit wasted computational resources. Predictable training behavior allows efficient scaling up experiments.
3. Intuitive Semantic Image Editing
- High disentanglement in the W latent space leads to semantic style vectors controlling specific visual attributes. This lends itself perfectly to image editing use cases.
- By tuning attributes of interest corresponding to particular style vectors, powerful applications like aging faces, altering hair color/style, manipulating expressions, etc. can be achieved without affecting other image aspects.
4. Flexible Architecture
- StyleGAN provides ample flexibility both during setup and post-training for extensive tweaking based on application needs.
- Generator/discriminator configurations, regularisation penalties, and data augmentation strengths are all easily customizable with an indicator-based selection strategy.
- GAN inversion can encode real images in latent space allowing combining styles from real and generated data. Powerful avenue for exploring new image manipulations.
5. Easy Domain Adaptation
- Pre-trained StyleGAN models for faces can rapidly adapt to new domains (animals, characters, etc) via simple fine-tuning. A few thousand images can already produce great quality results owing to base model transfer learning.
- Generic models can also be trained from scratch for custom domains by utilising robust training strategies evolved across StyleGAN iterations.
Limitations of StyleGANs
1. Compute-Intensive
- Training and inference with StyleGANs require powerful GPUs beyond the feasibility of individual users. Very computationally demanding.
- For example, the StyleGAN2 ADA paper used 8 V100 GPUs for a month to train FFHQ models. Requires optimization for accessibility.
2. Architectural Complexity
- The intricate dual-network mapper-synthesiser architecture makes customising and debugging StyleGANs non-trivial tasks.
- Architectural levers like several layers, normalisation schemes, etc. require extensive experimentation to adapt to new domains.
3. Training Instability
- Despite improvements in later versions, training instability is not eliminated especially for more complex datasets.
- Cutting-edge versions like StyleGAN3 are harder to train robustly owing to techniques like noise injection across generators.
4. Image Artefacts
- Subtle artefacts like blurred eyes, missing elements, and floating parts persist in some generated samples limiting perceptual quality.
- Constraints to enforce spatial coherence across objects can help overcome such issues.
5. Potential Misuse
- Like any powerful tech, StyleGANs also carry risks of misuse to generate fake/offensive media.
- Responsible AI practices around monitoring misuse, and watermarking AI-generated media are important to implement.
Conclusion
To recap, StyleGANs are new age generative models that singularly unite photo realism, modifications through meaningful control of characteristics, predictable coaching practices, and so on. New developments have resolved several of their early weaknesses concerning unpredictable preparation and irregular visual elements.
Generative adversarial networks have enhanced their style transfer abilities through architectural and methodological refinements. Streamlined design, disentangling of design aspects, and introducing noise at multiple stages have made StyleGANs potent image engines. Their functionalities and employments are likely to expand enormously through studies innovating in this area.
As an AI-focused software development company, Codiste specializes in building, deploying, and scaling next-gen deep learning solutions like StyleGANs on cloud and edge devices. Through Codiste's expertise in neural network architecture refinement, robust AI model design methodology, and efficient machine inference implementation, organizations can swiftly experiment with and mass produce artificial intelligence innovations across sectors, such as generative media content synthesis.